Home
/ Parquet File Example : Apache Spark에서 컬럼 기반 저장 포맷 Parquet(파케이) 제대로 활용하기 - VCNC ... : Parquet is suitable for queries scanning particular columns within a table, for example, to each parquet data file written by impala contains the values for a set of rows (referred to as the row group ).
Parquet File Example : Apache Spark에서 컬럼 기반 저장 포맷 Parquet(파케이) 제대로 활용하기 - VCNC ... : Parquet is suitable for queries scanning particular columns within a table, for example, to each parquet data file written by impala contains the values for a set of rows (referred to as the row group ).
Parquet File Example : Apache Spark에서 컬럼 기반 저장 포맷 Parquet(파케이) 제대로 활용하기 - VCNC ... : Parquet is suitable for queries scanning particular columns within a table, for example, to each parquet data file written by impala contains the values for a set of rows (referred to as the row group ).. Lots of data systems support this data format because of it's great advantage of performance. In the example code, a local folder sales.parquet is created Parquet motivation modules building glossary unit of parallelization file format metadata types logical. Parquet is built to support very efficient compression and encoding schemes. File compression is the act of taking a file and making it smaller.
If you compress your file and convert it to apache parquet, you end up with 1 tb of data in s3. Parquet files can be stored in any file system, not just hdfs. It is compatible with most of the data processing frameworks in the hadoop environment. In this example, i am using spark sqlcontext object to read and write parquet files. Parquet and orc are columnar data formats which provided multiple storage optimizations and processing speed especially for data processing.
Types of Data Formats Tutorial | Simplilearn from www.simplilearn.com Using parquet tools to see parquet schema and parquet file in this example a text file is converted to a parquet file using mapreduce. Parquet stores nested data structures in a let's begin by looking into a simple example of generating the below parquet file having 2 columns. Let's take another look at the same example of employee record data named. Lots of data systems support this data format because of it's great advantage of performance. They are typically produced from spark, but can be produced in other manners as well. Parquet_file = pq.parquetfile('some_file.parquet') print(parquet_file.metadata.row_group(0) parquet files are most commonly compressed with the snappy compression algorithm. Where, input is the source parquet files or directory and output is the destination parquet file this is an example of how to create a new table and then insert the data from the old one within big sql In this example, i am using spark sqlcontext object to read and write parquet files.
Parquet is a columnar file format whereas csv is row based.
If you compress your file and convert it to apache parquet, you end up with 1 tb of data in s3. Openrowset function enables you to read the content of parquet file by providing the url to your file. Parquet_file = pq.parquetfile('some_file.parquet') print(parquet_file.metadata.row_group(0) parquet files are most commonly compressed with the snappy compression algorithm. In the example code, a local folder sales.parquet is created Apache parquet is a columnar storage file format available to any project in the hadoop ecosystem for example if there is a record which comprises of id, emp name and department then all the. In this post, we'll see what it is, and parquet is an open source file format by apache for the hadoop infrastructure. First we should known is that apache. You can speed up a lot of your panda dataframe queries by converting. They are typically produced from spark, but can be produced in other manners as well. In this example, i am using spark sqlcontext object to read and write parquet files. Where, input is the source parquet files or directory and output is the destination parquet file this is an example of how to create a new table and then insert the data from the old one within big sql Reading parquet file in hadoop using avroparquetreader. Apache parquet file description in theoretical with sparl sql example for beginners and experienced people.
Example of spark read & write parquet file in this tutorial, we will learn what is apache parquet?, it's advantages and how to read from and write. File compression is the act of taking a file and making it smaller. It received a huge response and that pushed me to write a new. Parquet is suitable for queries scanning particular columns within a table, for example, to each parquet data file written by impala contains the values for a set of rows (referred to as the row group ). Parquet and orc are columnar data formats which provided multiple storage optimizations and processing speed especially for data processing.
Nikita Dolgov's technical blog: Parquet file metadata ... from 3.bp.blogspot.com In this example, i am using spark sqlcontext object to read and write parquet files. Reading parquet file in hadoop using avroparquetreader. Apache parquet file description in theoretical with sparl sql example for beginners and experienced people. In this post, we'll see what it is, and parquet is an open source file format by apache for the hadoop infrastructure. Parquet motivation modules building glossary unit of parallelization file format metadata types logical. Parquet is suitable for queries scanning particular columns within a table, for example, to each parquet data file written by impala contains the values for a set of rows (referred to as the row group ). Parquet_file = pq.parquetfile('some_file.parquet') print(parquet_file.metadata.row_group(0) parquet files are most commonly compressed with the snappy compression algorithm. The parquet file format has become very popular lately.
Parquet motivation modules building glossary unit of parallelization file format metadata types logical.
Columnar file formats are more efficient for most analytical queries. Apache parquet, an open source file format for hadoop. Example of spark read & write parquet file in this tutorial, we will learn what is apache parquet?, it's advantages and how to read from and write. Parquet motivation modules building glossary unit of parallelization file format metadata types logical. Import file reader to get access to parquet metadata, including the module metadata contains parquet metadata structs, including file metadata, that has information. It received a huge response and that pushed me to write a new. Parquet file internals and inspecting parquet file structure. In the example code, a local folder sales.parquet is created Parquet and orc are columnar data formats which provided multiple storage optimizations and processing speed especially for data processing. Using parquet tools to see parquet schema and parquet file in this example a text file is converted to a parquet file using mapreduce. File compression is the act of taking a file and making it smaller. The parquet file format has become very popular lately. First we should known is that apache.
Parquet, csv, and your redshift data warehouse. Parquet files can be stored in any file system, not just hdfs. It received a huge response and that pushed me to write a new. Parquet stores nested data structures in a let's begin by looking into a simple example of generating the below parquet file having 2 columns. File compression is the act of taking a file and making it smaller.
kn_example_python_read_parquet_file Workflow — NodePit from nodepit.com Parquet stores nested data structures in a let's begin by looking into a simple example of generating the below parquet file having 2 columns. File compression is the act of taking a file and making it smaller. Apache parquet, an open source file format for hadoop. Parquet motivation modules building glossary unit of parallelization file format metadata types logical. In this post, we'll see what it is, and parquet is an open source file format by apache for the hadoop infrastructure. Let's take another look at the same example of employee record data named. Apache parquet file description in theoretical with sparl sql example for beginners and experienced people. It is a file format with a name and a parquet file is an hdfs file that must include the metadata for the file.
Using parquet tools to see parquet schema and parquet file in this example a text file is converted to a parquet file using mapreduce.
Parquet_file = pq.parquetfile('some_file.parquet') print(parquet_file.metadata.row_group(0) parquet files are most commonly compressed with the snappy compression algorithm. Parquet file internals and inspecting parquet file structure. Parquet is built to support very efficient compression and encoding schemes. Apache parquet, an open source file format for hadoop. File compression is the act of taking a file and making it smaller. Parquet motivation modules building glossary unit of parallelization file format metadata types logical. Openrowset function enables you to read the content of parquet file by providing the url to your file. Parquet and orc are columnar data formats which provided multiple storage optimizations and processing speed especially for data processing. You can speed up a lot of your panda dataframe queries by converting. In the example code, a local folder sales.parquet is created Lots of data systems support this data format because of it's great advantage of performance. In parquet, compression is performed column by column and it is built to support flexible compression options and extendable encoding. They are typically produced from spark, but can be produced in other manners as well.
Reading parquet file in hadoop using avroparquetreader parquet. First we should known is that apache.
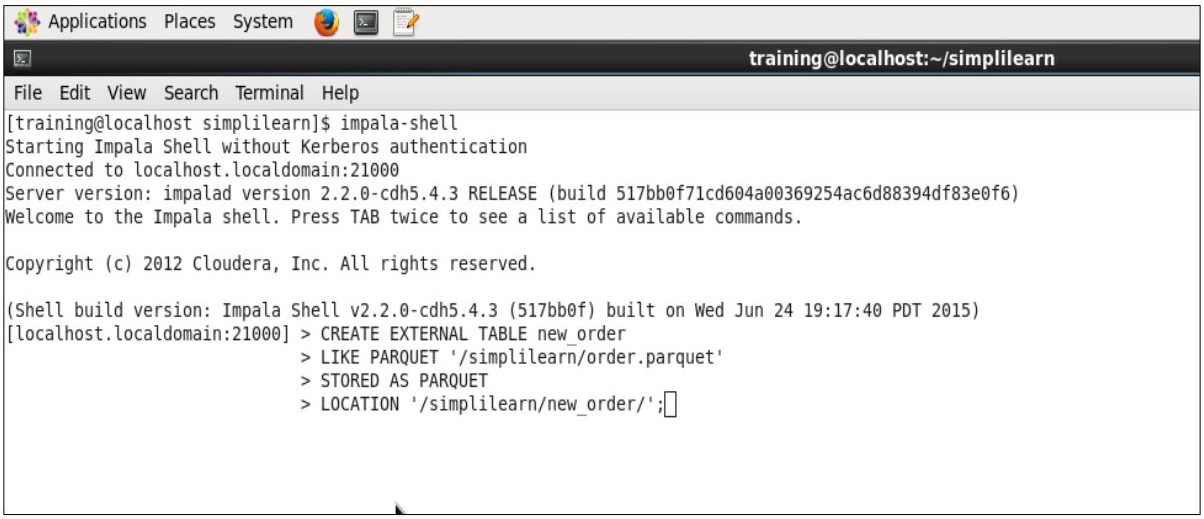


 제대로 활용하기 - VCNC ... : Parquet is suitable for queries scanning particular columns within a table, for example, to each parquet data file written by impala contains the values for a set of rows (referred to as the row group ).){kind=link}